
文章主題:
本篇文章續借「總體經濟模型 – 復甦期 – 進出口與投資」一文,本篇文章的重點在於討論如何使用消費與就業的相關數據來判斷復甦期的到來。
判斷復甦期所使用數據:
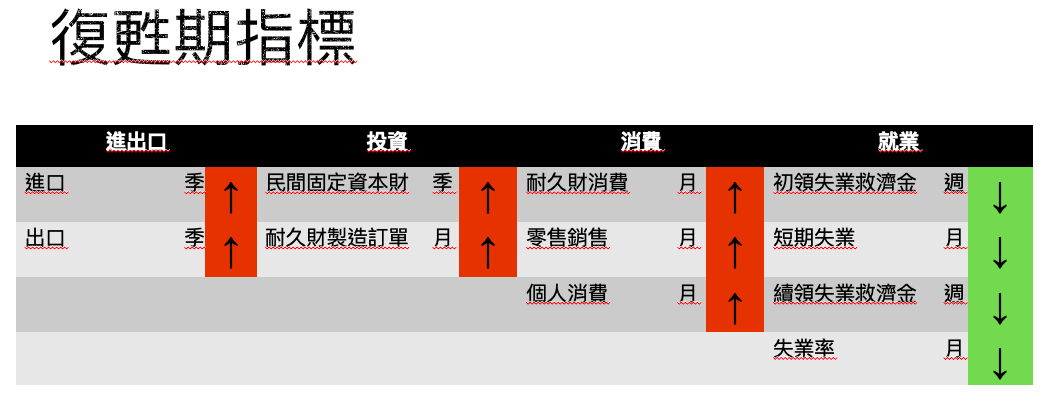
消費:
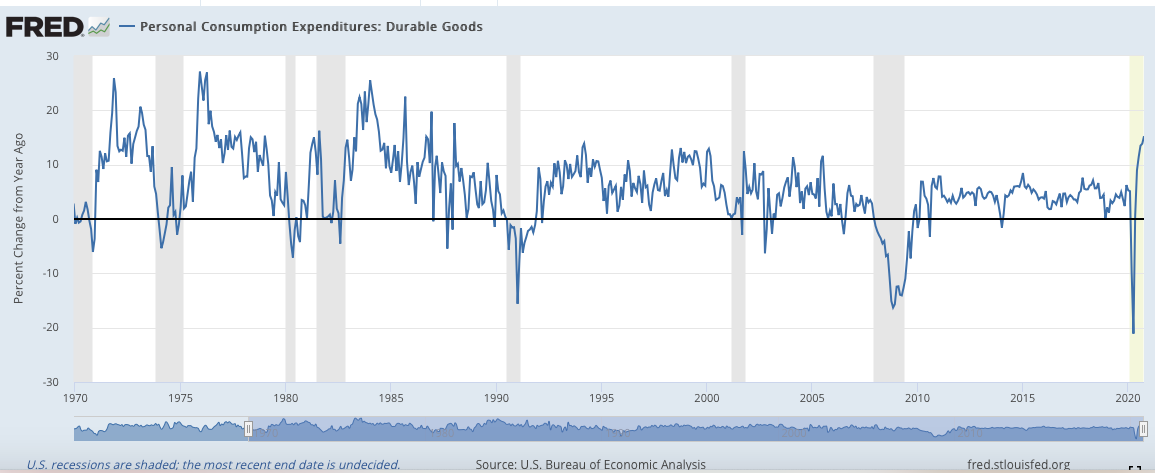
1)耐久財消費(Personal Consumption Expenditures: Durable Goods)(月)
耐久財消費顯示的是該國的私人消費者在一個月期間內所購買的耐久財的總金額。這個數值是一個能夠很好的體現居民消費力的數據。當耐久財消費的數據增加時,說明居民購買力提升,反之,則說明,居民購買力衰退。
下圖中使用了耐久財消費的YOY,由於數據是每月一次,因此波動幅度較大。在下圖中,需要重點關注的數據與0線的交叉點。當耐久財消費在長期處於0線下方,在谷底發生向上突破0線反彈時,可以確定景氣復甦期的到來。
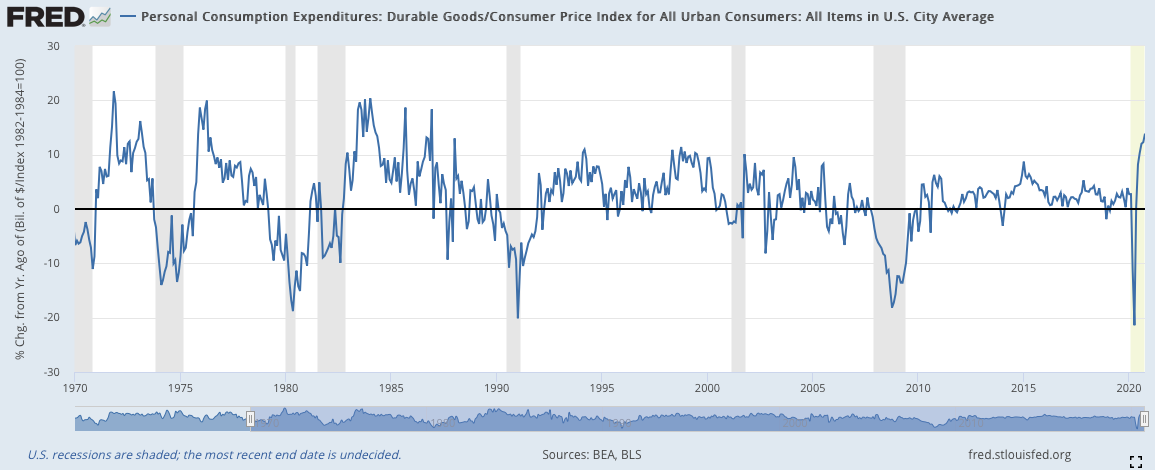
通貨膨漲處理之後的版本見下圖:(原數據/當時的CPI指數,而後進行YOY處理):
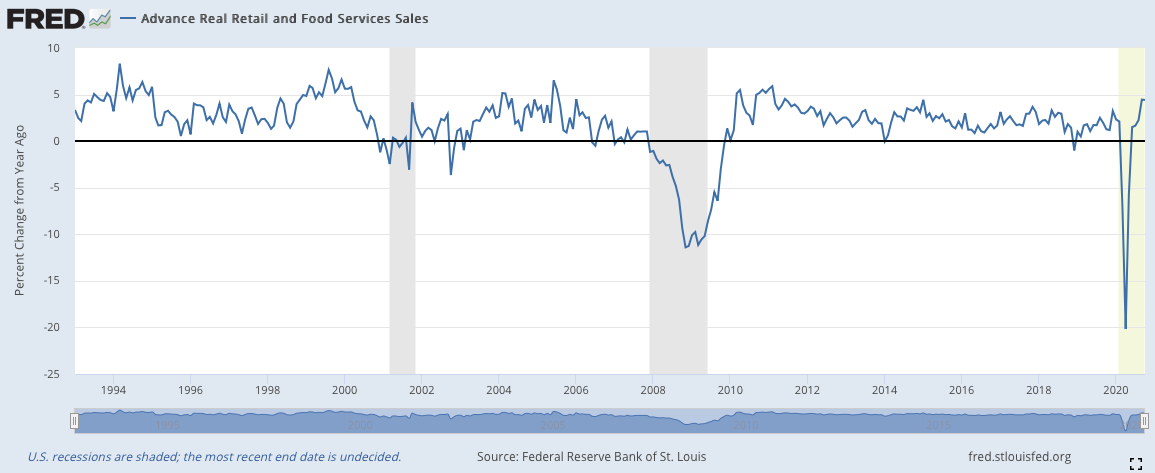
2)零售銷售(Advanced Real Retail and Food Services Sales)(月)
零售銷售指的是當前一個月零售和食品銷售的總額。它的意義在於體現全體國民對於這類型商品的購買力。由於零售與食品是可消耗的必需品,這導致其消費的波動幅度相較耐久財而言小了許多。此外,我們使用的(Advance)數據實際上是美聯儲所做的一個樣本估計,通過選擇一系列公司企業的銷售額來進行推估,因此數據的處理和推出比起真實數據要快速許多,除此以外名稱中的(Real)說明數據還去處理通貨膨脹的影響。真實的數據叫做(Real Retails and Food Services Sales: Total)而沒有經過通貨膨脹處理的版本叫做(Advance Retail Sales: Retail and Food Services, Total)。在推估的數據會在真實數據被推出之後被覆蓋,因此,現在我們看到的數據版本是已經覆蓋過的真實版本。
零售銷售YOY中,可以看到,這個數據的波動幅度明顯比前面的耐久財消費要少很多。並且,它低於0線的時間長,也低於耐久財消費,這是因為零售銷售比較類似生活必須用品。但它的使用方法與耐久財消費比較類似,都是在低於0線的時候,觀察數據向上突破0線的時機。
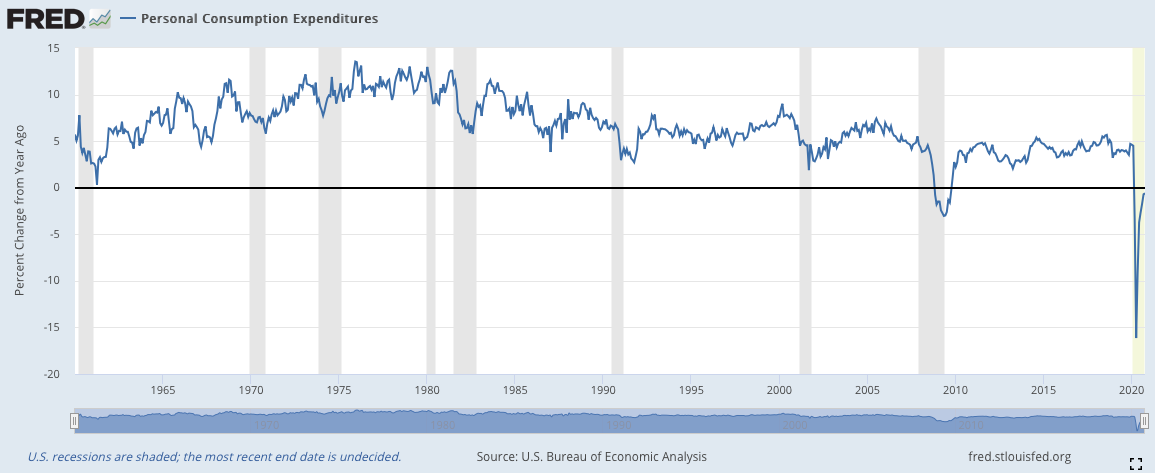
3)個人消費(Personal Consumption Expenditure)(月)
個人消費包括耐久財與零售銷售,因此這個數據呈現的是民間消費金額的總額。這個數據也有調整過通貨膨脹的版本,不過歷史數據時間過短,難以進行有效的回測。因此使用這個數據的時候要小心,當然我們也可以自己手動進行調整,
下圖使用了個人消費YOY,這個數據的使用方法原本應該與前兩個數據相同,不過由於沒有進行通貨膨脹處理,因此長期數據都位於0線以上。
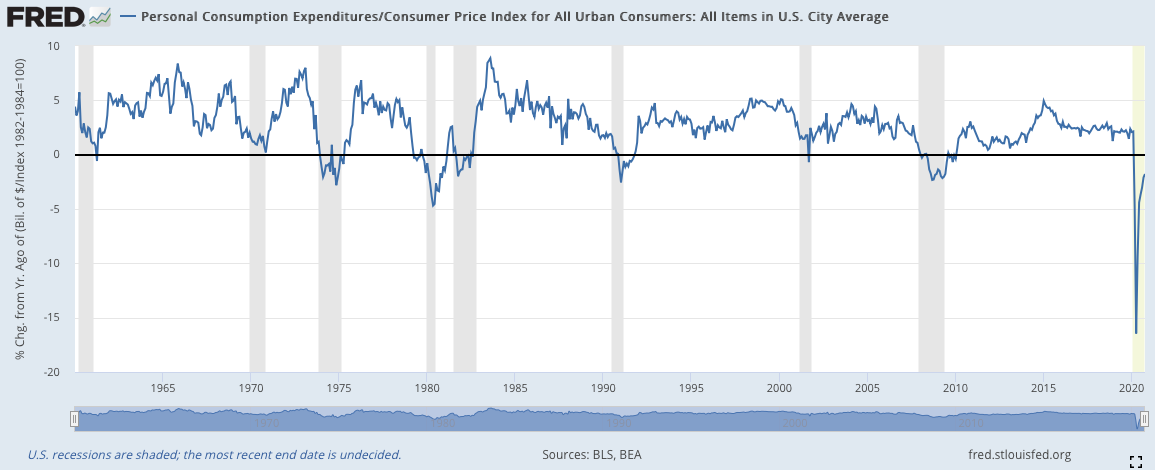
通貨膨漲處理之後的版本見下圖:(原數據/當時的CPI指數,而後進行YOY處理)
就業:
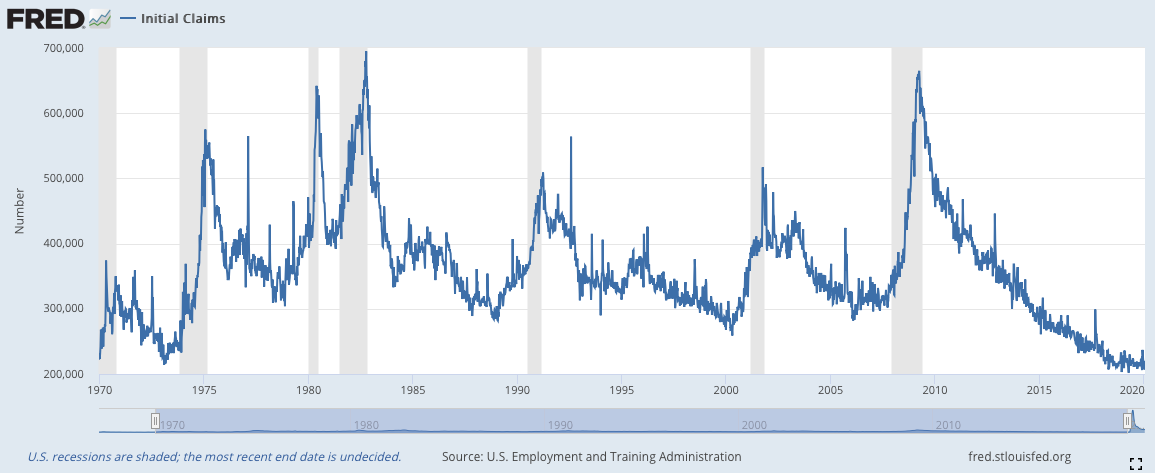
1)初領失業救濟金人數(Initial Claims)(周)
Initial Claim 這個詞本身的意思是員工在結束與雇主的契約關係,而後進入失業狀態時,向政府機關申請領取失業救濟保險所給予的失業救濟金時的申請書。通過計算政府部門每週收到的申請的數量可以推估這周內新增的失業人數。因而,這個數據是能夠最敏感地體現當前社會的就業情況的就業數據,而就業的數據有能進一步體現社會當前的生產力狀況與消費狀況。
若初領失業救濟金的人數增加,說明企業的生產力超過消費者的需求,因此需要通過裁減人手來達到減少損失的目的,但是失業人數的新增又會導致消費者的需求進一步減少,公司又需要裁減額外的人手,因此陷入惡性循環。但是,這個惡性循環不會一直持續,它的規模會逐漸減少。若初領失業救濟金人數減少,說明當前新增失業人數放緩,因此公司不在需要裁減更多的人手,因為當前生產力符合消費者的需求,這又進一步彌補了消費的缺失,進入良性循環。
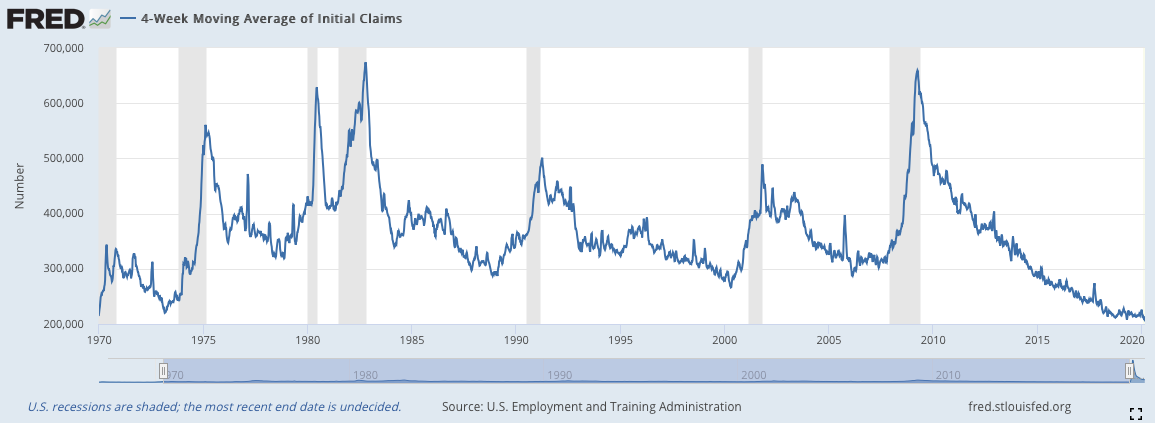
如下圖所見,每次初領失業救濟金人數出現連續性的大規模增加的時期都是蕭條時期(下圖去除了2020年三月的數據,因為數字過大導致前面年份的數據變化不明顯)。而當初領失業救濟金的人數出現高點反轉的時候就提示我們景氣已經恢復,復甦即將來到。這個數據所存在的問題是它的波動性,由於這個數據是每週推出,它的波動性也因此很高,容易使我們誤判高點反轉的位置。因此在模型中,我們使用其Moving Average(Moving Average的長短可以調整)。(下面的第二張圖就是四周Moving Average的效果圖)
MA4:
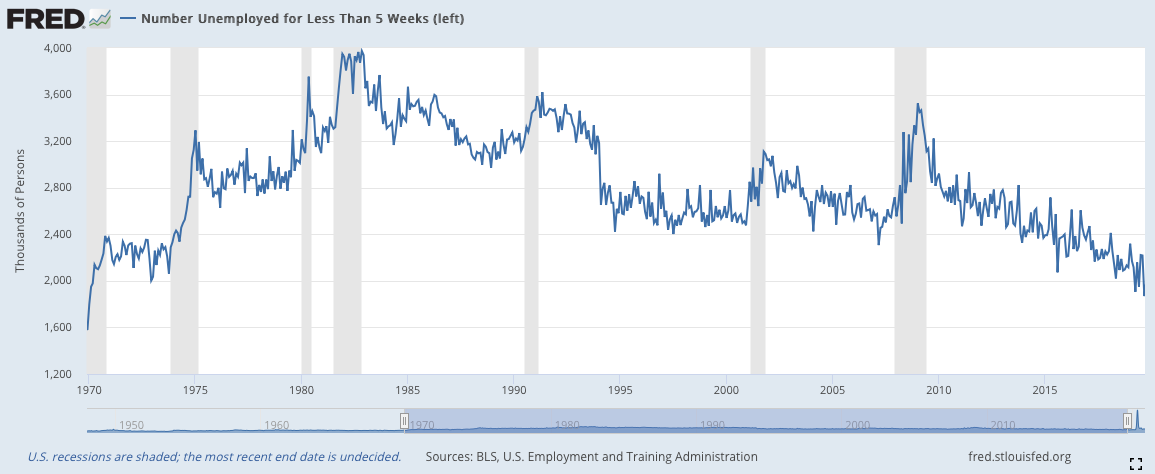
2)短期失業(Number Unemployed For Less Than Five Weeks)(月)
短期失業,顧名思義,指從失業開始到數據記錄當天少於5周的人。這個數據的使用邏輯和初領失業救濟金相對類似,這也是為什麼我會把二者放在相近的位置討論。短期失業數與初領失業救濟金人數都能夠很敏銳地體現當前經濟體的就業狀態。
當下圖中的數據與先前的時期相比處於高檔時,就說明當前經濟體的生產力出現相對衰退,而這種現象大部分出現在景氣衰退時期。而當短期失業從高檔期下降時,就表示經濟體的生產力出現恢復徵兆,若是這個判斷與其他數據的判斷匹配的話,就說明復甦期到來的機率很高。
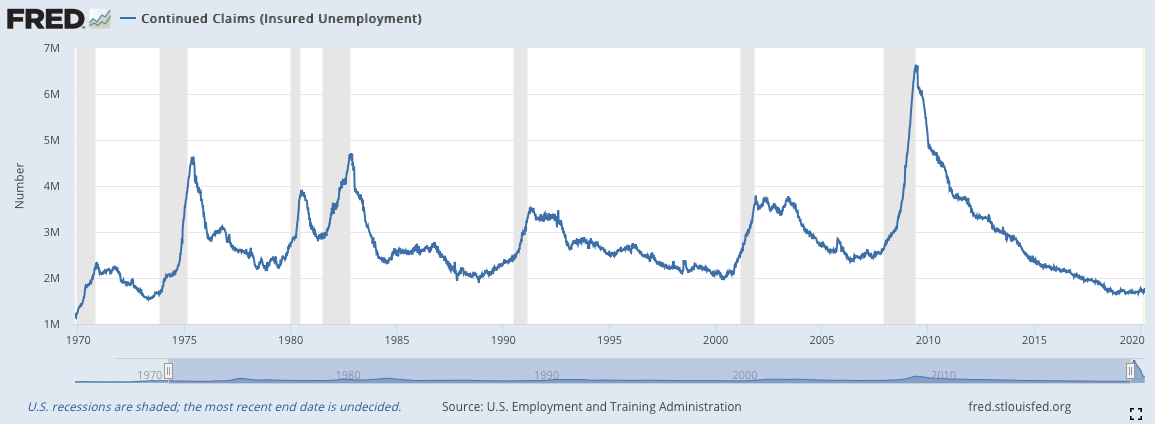
3)續領失業救濟金(Continued Claims)(周)
續領失業救濟金與初領失業救濟金的關係很明顯,從名字裡就能看出來了。當一個人在申請失業救濟金後的一個禮拜依舊保持失業狀態,並且又一次填寫了救濟金領取申請時,就屬於續領失業救濟金的計算範疇。這個數據與短期失業的數據有點類似,能夠體現短期內經濟體的就業水平與生產力。但是兩個數據的週期不一樣(周vs月)並且統計的部門與統計的方式也不一樣(美國就業和培訓管理局,使用計算收到的申請數;美國勞工統計局,樣本統計)。
就結果來看,這個數據是目前所提到過的三個就業數據中最為遲緩的,這是因為續領失業救濟金的數量是累加的,而不是像初領失業救濟金一樣是單次的,這與數據本身的屬性有關係。
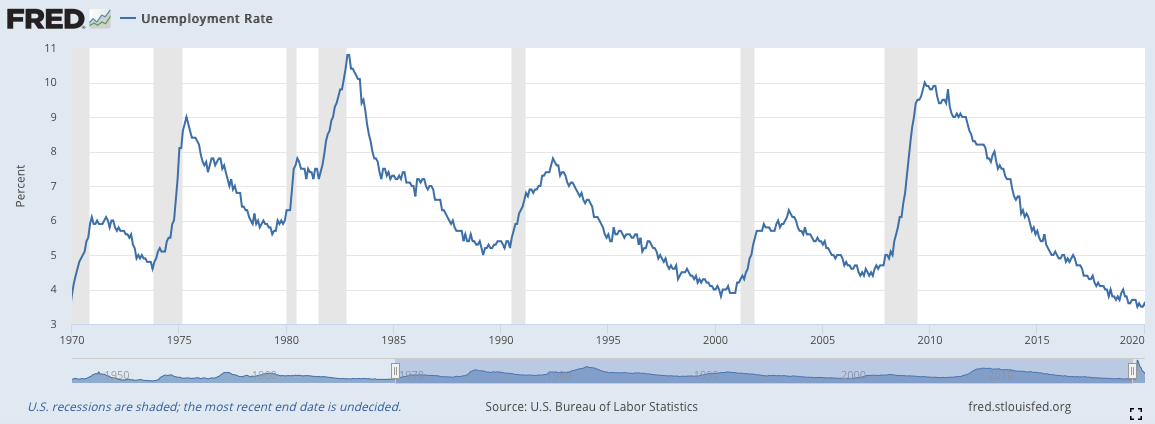
4)失業率(Unemployment Rate)(月)
失業率應該就不用介紹了,這應該是大家最為熟悉的經濟數據之一。能夠有效的體現經濟體當前的生產力狀況。然而,這個數據雖然是每月推出的,但是其數據功能卻相比上述的其他三個數據要落後許多。這是因為公司企業內在的屬性所影響的。一個公司在面對需求短缺與景氣蕭條時,會立刻通過裁減非必須人員來減少開支,但是會保留足以維持公司運營的關鍵人才。在景氣恢復時,公司不會立刻進行招募,因為公司依舊可以負荷當前的微微增加的需求量,甚至有些會進行第二輪裁減,擴大獲利來挽回蕭條期的損失。只有等到消費需求持續增長直至公司當前的人員數已經不夠負荷時,公司才會開始進行招聘,這個時候距離蕭條期的開始已經有一段時間。
正是因為上面說的這個原因,所以初領失業救濟金與短期失業的人數才能夠特別敏感地體現當前經濟體的景氣狀況,因為他們可以有效的察覺公司在蕭條期時的裁員行為,當這個行為一旦開始減緩,這不代表失業率開始減少,而是能夠體現景氣寒冬已經結束了。
見下圖,失業率的數據雖然比較遲緩,但是它的下降一旦確立,準確性相當高,很少會有再反彈的情況。
小結論:
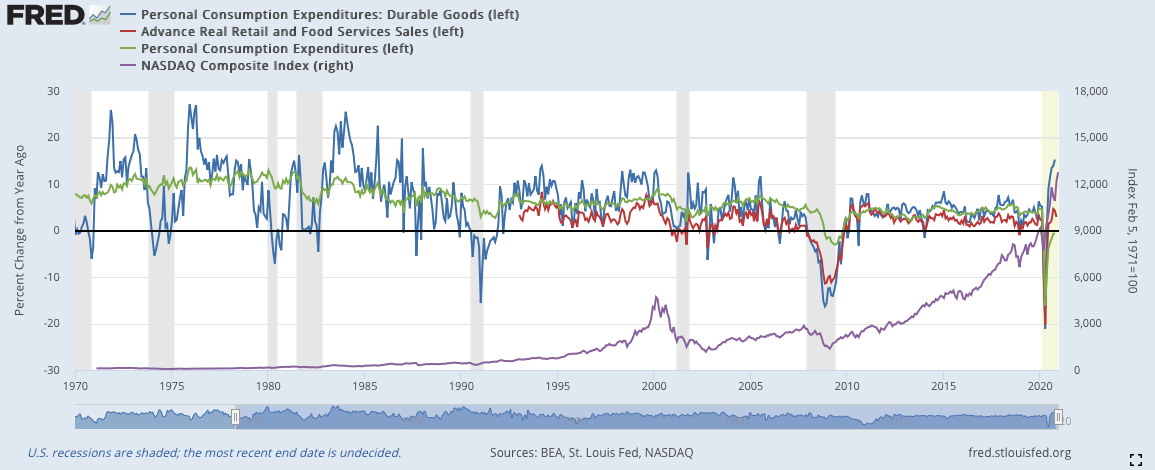
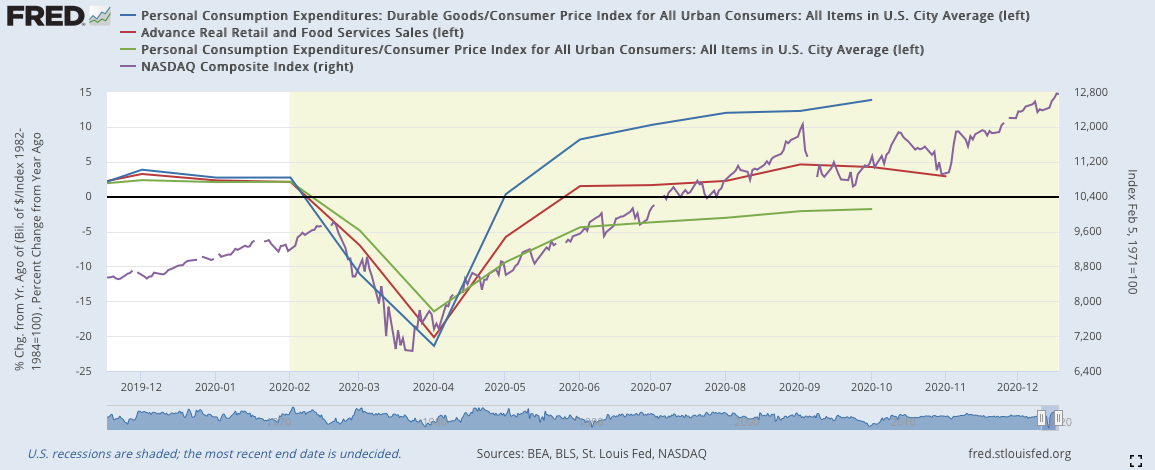
1)將消費數據與納斯達克數據對比:
藍色:耐久財消費(左軸)
紅色:零售銷售(左軸)
綠色:個人消費(左軸)
紫色:納斯達克(右軸)
通膨處理前:
通膨處理後:
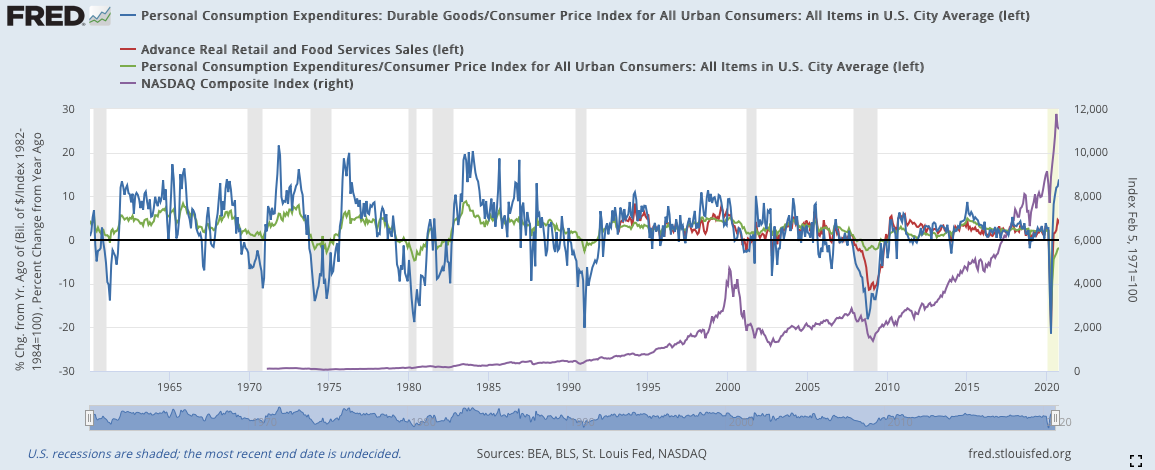
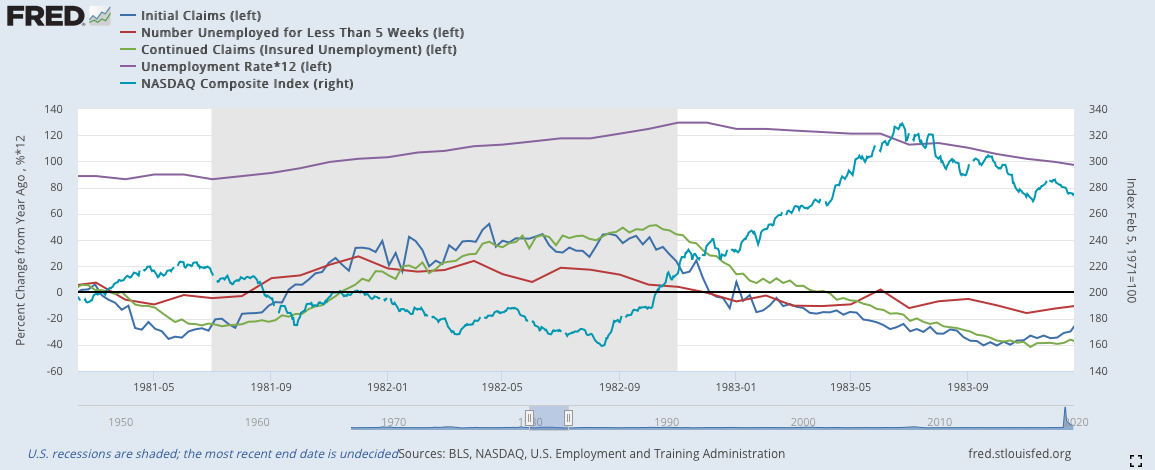
1990:
藍線與綠線在1991年二月的時候就已經反彈(減少速度放緩)。此時紅線還沒有數據因而沒有顯示。
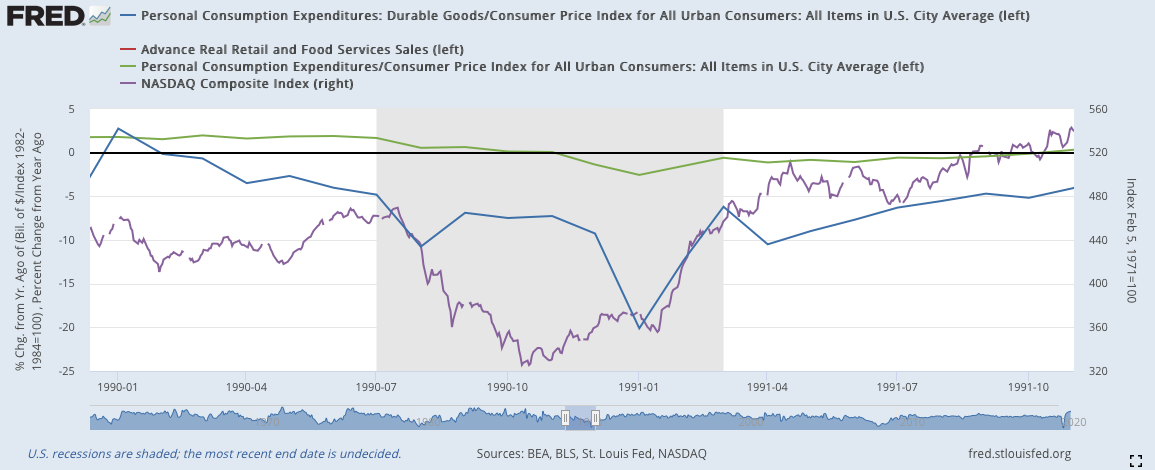
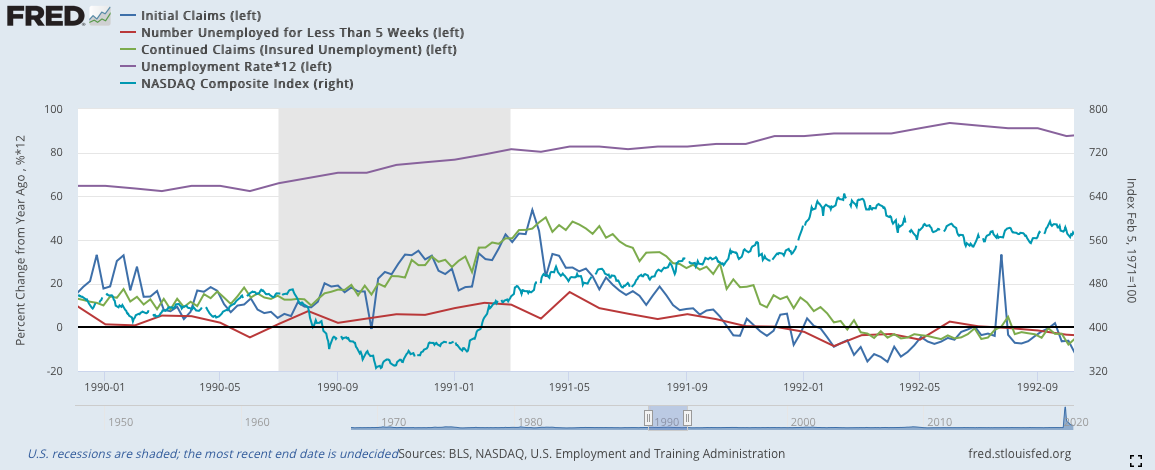
2000:
在2001年10月時,三個消費數據同步反彈,甚至突破零線向上,隨後股票也的確持續上漲,在11月的時候上漲幅度縮小,12月漲幅再度見小,可依舊保持在領先上方。按照一般情況來說,應該確立復甦期了,但2000年情況較為特別,股市在出現一個長達一個季度的反漲後,隨後出現第二波的蕭條。如果按照消費面的數據來看的話,這個第二波蕭條時不應該發生的。因此,這個事件型的蕭條,通過消費數據是無法覺察的,要通過其他數據才能看出來。
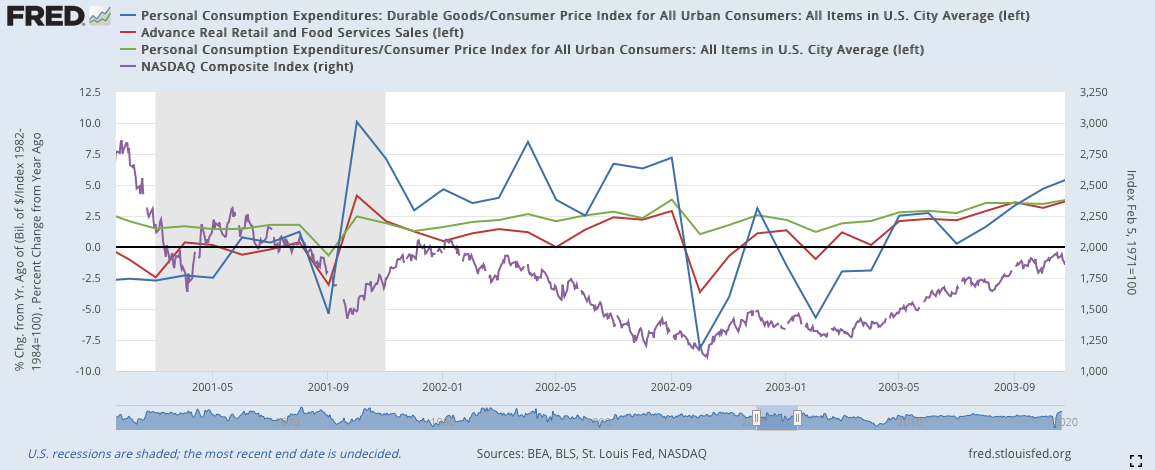
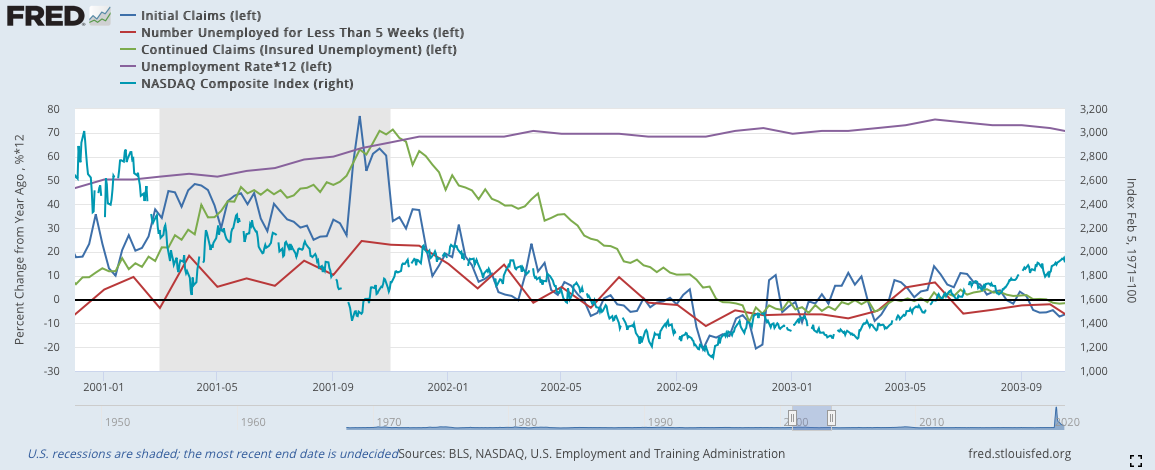
2008:
2008年12月到一月時,三個數據就出現了短暫的緩緩上揚,幅度不大,其中耐久財消費的幅度最大,但在之後的二月份又出現一次下跌。隨後三月開始,三線同步反彈,宣告復甦期的正式到來。
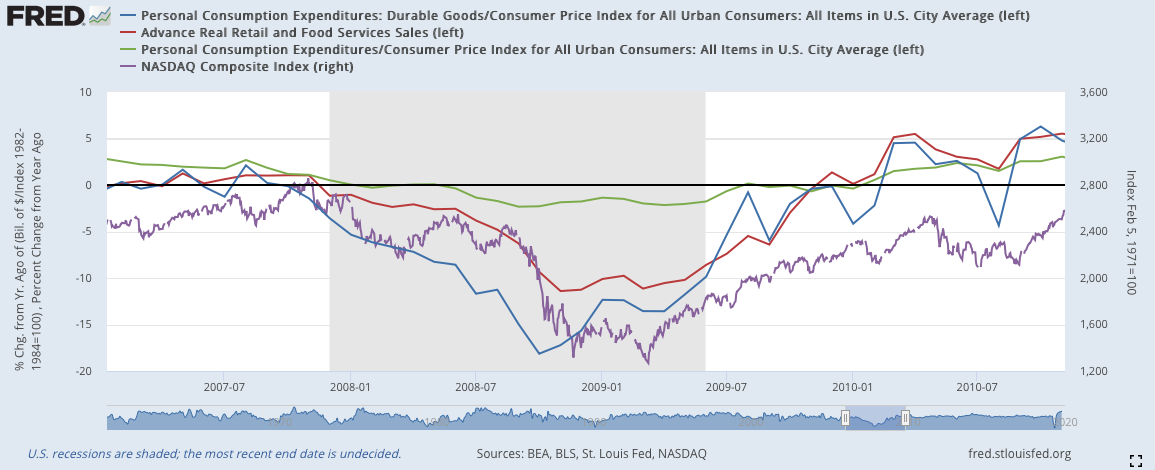
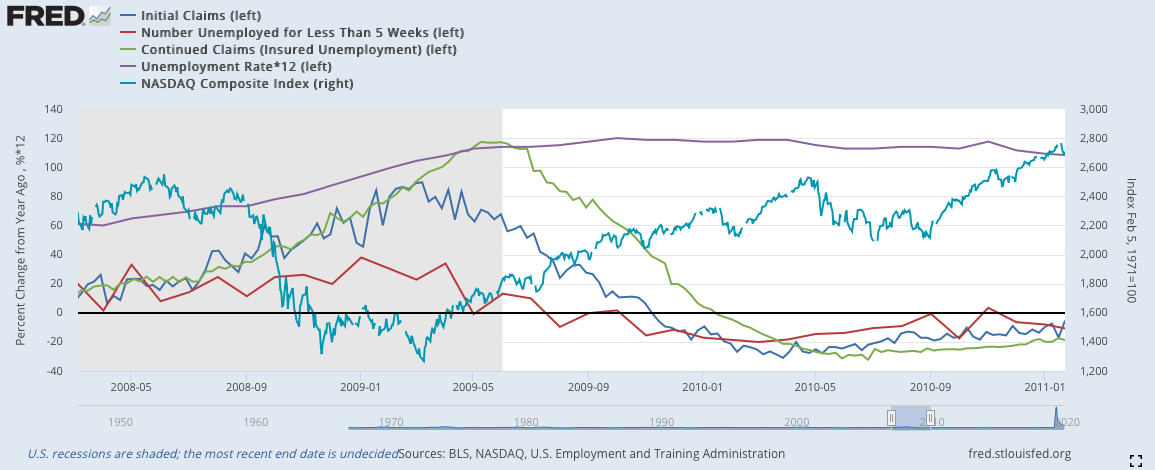
2020:
2020年受到疫情影響,在二月到三月消費數據出現重大挫折,之後在四月出現三線共同反彈,確立復甦期到來。
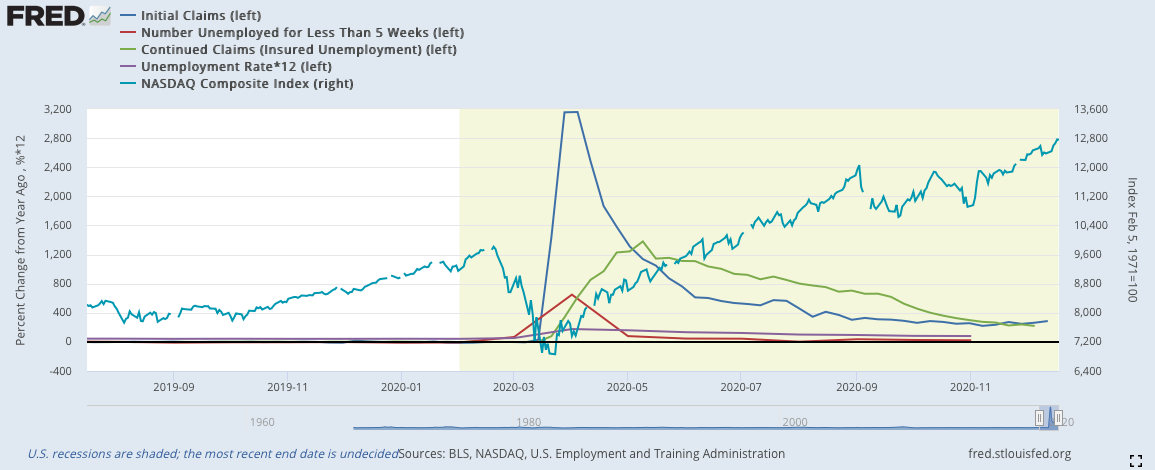
2)將就業數據與納斯達克對比:
由於失業數據各自的數據大小差異很大,難以全部以適當的大小進行可視化,因此我這邊採用YOY來全部嵌入同一張圖裡,但在模型中還是使用原始數據。同時,由於2020年三月的數據增加過於大,所以在前文中的2020的部分都被我剪掉,這樣才能看到數據應有的線型形狀,若沒有這樣處理就會向下圖一樣,只剩下2020年突出的數據。
*由於失業率的數據比例過於小,我將失業率乘以12來使其符合其他數據的波動程度
深藍:初領失業救濟金(左軸)
紅色:短期失業(左軸)
綠色:續領失業救濟金(左軸)
紫色:失業率(左軸)(乘以12)
淡藍:納斯達克指數(右軸)
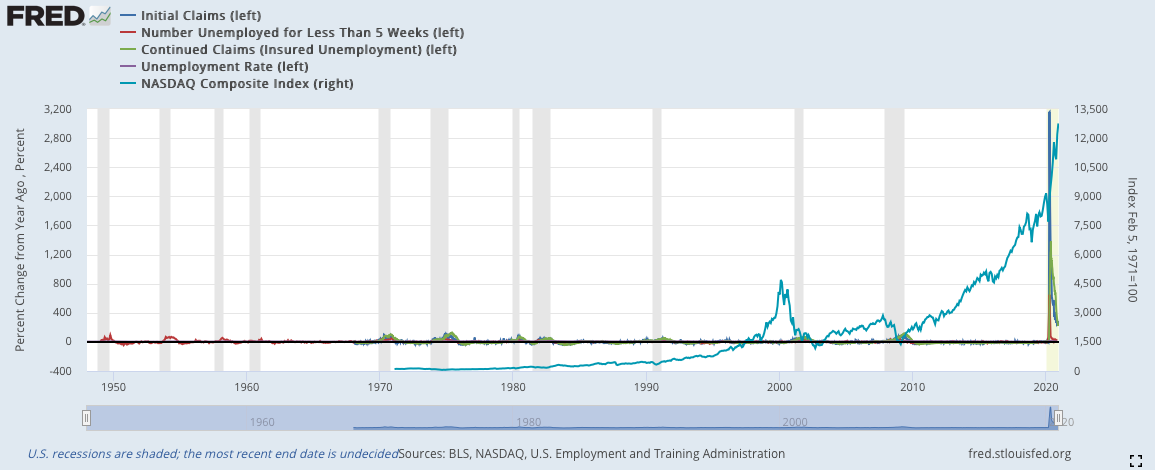
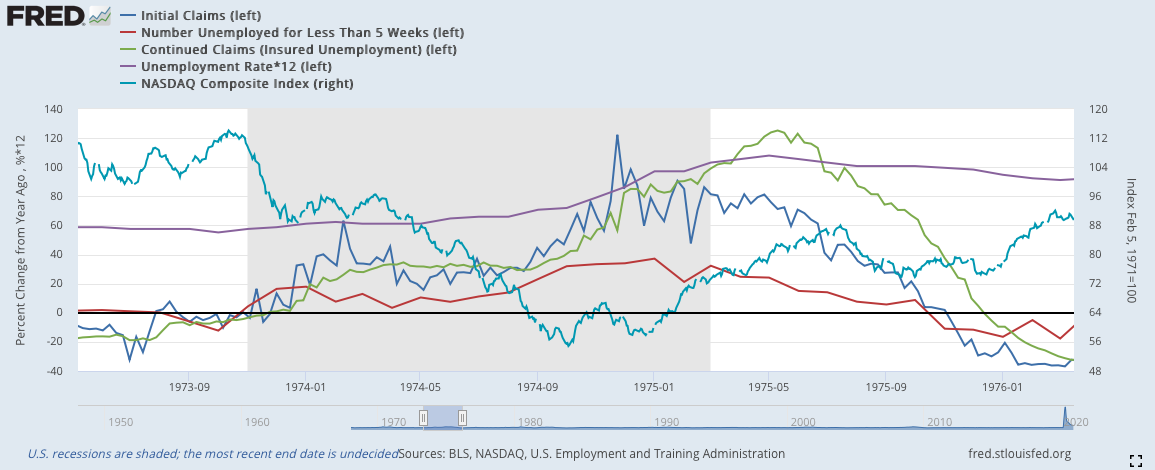
失業相關的數據歷史數據完備,因而最早可以推倒1974年的蕭條。數據的走向相當類似,基本就是初領失業救濟金率先下降,出現徵兆;隨後,短期就業下降;續領失業救濟金在兩者下降幾週後也會跟隨;最後,失業率才會慢慢地下降。
1974:
1980:
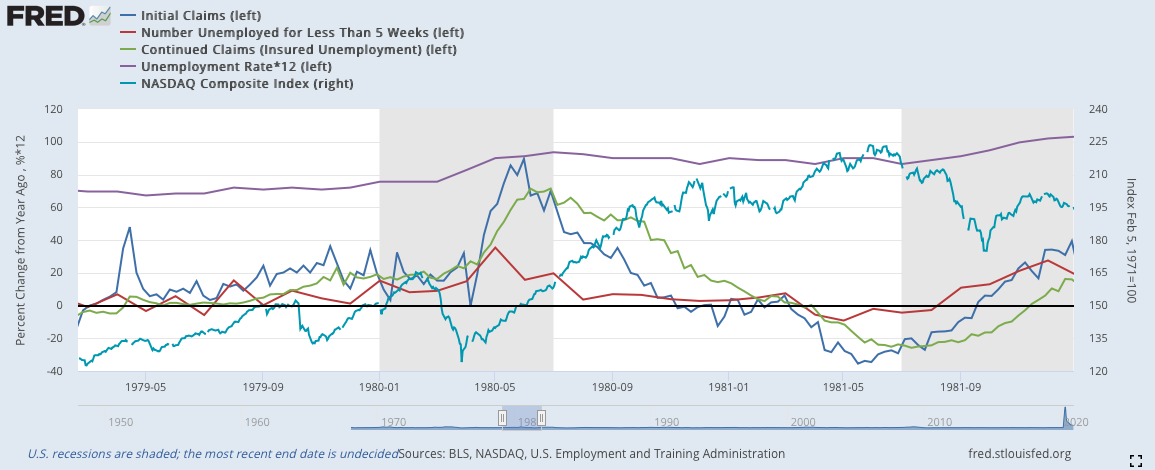
1981:
1990:
2000:
2008:
2020:



留言區